2.1 The background penalty 5
2.2 The observation penalty 6
3.1 The gradient of
3.2 Evaluating the gradient of
3.3 The adjoint method 11
DARC Technical Report No. 2
Ross N. Bannister
Data Assimilation Research Centre, University of Reading, UK
Last revised: 16th October 2001 / 29th August 2007
All forecast models, whether they represent the state of the weather, the spread of a disease, or levels of economic activity, contain unknown parameters. These parameters may be the model's initial conditions, its boundary conditions, or other tunable parameters which have to be found for a realistic result. Four dimensional variational data assimilation, or "4d-Var", is a method of estimating this set of parameters by optimizing the fit between the solution of the model and a set of observations which the model is meant to predict. In this context, the procedure of adjusting the parameters until the model 'best predicts' the observables, is known as optimization. The "four dimensional" nature of 4d-Var reflects the fact that the observation set spans not only three dimensional space, but also a time domain.
For weather forecasting, the method of 4d-Var has been adopted by many numerical weather prediction (NWP) agencies as it is flexible enough to allow a range of atmospheric observations of many different types to be digested within a framework of a numerical model of the atmosphere. This has proved to be a valuable tool in estimating the initial conditions of a weather prediction model, which are essential for a good forecast. In 4d-Var the method supersedes the simpler and less expensive "3d-Var", in which no proper account is made of the time of which an observation is made. Although the method of 4d-Var described in these notes is not restricted to any particular system, the application described here has a NWP model at its core, and the parameters to be determined are the model's initial conditions.
The optimization problem is quite demanding and all of the following issues must be considered:
All of the above aspects are automatically taken into account in the method of 4d-Var. Optimization, as we have defined it, should be regarded as a class of inverse problem. Indeed, we assume that the forward problem is soluble. That is, given a set of initial conditions, a set of forward models can be run to predict the observations. The most important forward model is the core NWP forecast model which gives the evolution in time of the model's state. Other forward models are important but secondary. These have as their input a model state (pertaining to a particular time), and predict the observables at that time. Examples of such predicted observations commonly used in an NWP context are of the meteorological variables (wind, temperature and humidity) interpolated from the model grid to the position of an instrument (in a field station, or on a sonde or aircraft), a layer mean mixing ratio (e.g. water vapour) as derived in a satellite profile, or a radiance measurement as observed by satellite. The predicted 'observations' may or may not match the actual observations; this depends on the choice of initial conditions (and on the suitability of the models). We are interested in solving the inverse problem which can be posed as follows: what set of initial conditions will seed the models to best predict the known observations? Such inverse problems are in general much harder to solve than the forward analogue. Indeed, the inverse problem relies on the existence of the forward models themselves which are run many times in an iterative fashion to give the analysis (Fig. 1).
4d-Var is a powerful way of interfacing models and observations in this way. This is a difficult task as observations are generally not suitable for direct initialization of models. For the application of weather forecasting, it is sometimes confusing to understand our interest in initializing a model to run forward over time, some of which has already passed (after all, if observations have been made then the weather has happened). The answer is to develop a model state which is representative of the actual weather just before a forecast model is launched. This state is expected to yield the best possible forecast.
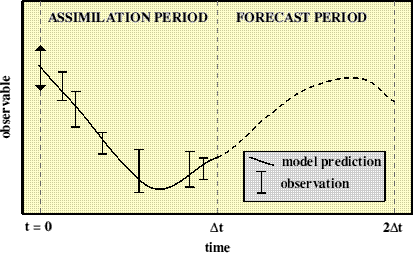
Figure 1: the model 'trajectory' - the model's prediction of an observable quantity (curve) - is shown which best fits the set of observations (bars). The height of the bars denote the degree of uncertainty in the measurements. The method of 4d-Var involves adjusting the model's initial conditions (bold arrow at ![]() ) for this best fit.
) for this best fit.
Although the principle product of data assimilation is to obtain well initialized forecasts, other important 'spin-offs' have emerged. Global and complete model analyses (four dimensional datasets of meteorological variables) are routinely produced from historical data to aid the science of climate. Well known examples include the European Reanalysis datasets of the European Centre for Medium Range Weather Forecasts (ERA-15 or ERA-40) and the global dataset of the National Center for Environmental Protection. The technique also provides a valuable quantification of model performance and a measure of observation quality.
The approach of this inverse modelling technique is to find the initial conditions of a model, ![]() , such as to minimize some scalar quantity,
, such as to minimize some scalar quantity, ![]() .
. ![]() is known as the cost or penalty function.
is known as the cost or penalty function. ![]() is a functional of the state vector
is a functional of the state vector ![]() , and is defined to be a global measure of the simultaneous misfit between
, and is defined to be a global measure of the simultaneous misfit between ![]() , the current guess of the true atmospheric state, and two independent 'versions' of the atmospheric representation. One of these versions is that according to the observations themselves, and the other is taken from a model forecast. The latest observations (for a manageable time slice of 6-12 hours) are contained in the vector
, the current guess of the true atmospheric state, and two independent 'versions' of the atmospheric representation. One of these versions is that according to the observations themselves, and the other is taken from a model forecast. The latest observations (for a manageable time slice of 6-12 hours) are contained in the vector ![]() . Using observations alone for the purpose of initializing a model is inadequate as measurements are not evenly spread over the atmosphere. Furthermore the number of degrees of freedom in the model (the size of the vector space,
. Using observations alone for the purpose of initializing a model is inadequate as measurements are not evenly spread over the atmosphere. Furthermore the number of degrees of freedom in the model (the size of the vector space, ![]() , describing
, describing ![]() ) far outweighs the number of reliable observations taken within the time period, and different observations do not necessarily provide independent pieces of information. To help overcome this problem a priori information is needed. This comes from a previous model forecast, and is the second version of the atmospheric state used in the cost function. This state is called the background,
) far outweighs the number of reliable observations taken within the time period, and different observations do not necessarily provide independent pieces of information. To help overcome this problem a priori information is needed. This comes from a previous model forecast, and is the second version of the atmospheric state used in the cost function. This state is called the background, ![]() , valid at time
, valid at time ![]() , serving as an information 'filler' for data voids.
, serving as an information 'filler' for data voids.
We can now proceed to define a form of ![]() which simultaneously penalizes a bad fit between (i) the model state
which simultaneously penalizes a bad fit between (i) the model state ![]() and the background, and the (ii) model state and the predicted observations [1]. The usual form of
and the background, and the (ii) model state and the predicted observations [1]. The usual form of ![]() reflects these two contributions (
reflects these two contributions (![]() and
and ![]() respectively):
respectively):
![]()
![]()
![]()
where here and in the remainder of this report, the model state, ![]() , applies to the initial time
, applies to the initial time ![]() (defined to be at the start of the current assimilation cycle) unless explicitly labelled otherwise. Other symbols are the following:
(defined to be at the start of the current assimilation cycle) unless explicitly labelled otherwise. Other symbols are the following: ![]() is the background error covariance matrix,
is the background error covariance matrix, ![]() is the set of observations made at time
is the set of observations made at time ![]() ,
, ![]() is the part of the forward model which predicts the observations based on the model's current state, and
is the part of the forward model which predicts the observations based on the model's current state, and ![]() is the observational error covariance matrix. The vector
is the observational error covariance matrix. The vector ![]() is known as a residual.
is known as a residual.
We have made various assumptions when writing down this cost function. Firstly, we have assumed that the errors are unbiased and Gaussian [1]. If the former condition is not met, and the biases are known, observations can be corrected in the preprocessing performed on the raw observations when compiling ![]() . Another assumption is that the model is 'perfect' over the assimilation period. This leads to the so-called strong constraint formalism as used in Eq. (1). We could write an alternative cost function with a third term which is the additional constraint which penalises model error. This would be an example of the weak constraint formalism [2].
. Another assumption is that the model is 'perfect' over the assimilation period. This leads to the so-called strong constraint formalism as used in Eq. (1). We could write an alternative cost function with a third term which is the additional constraint which penalises model error. This would be an example of the weak constraint formalism [2].
The compactness of the definition of ![]() in Eq. (1) is good for brevity, but the apparent simplicity is somewhat misleading, as the underlying operators are complicated and difficult to deal with. Before we explain why, let us describe each term. The form of each term is, assuming any non-linearity in the forward models to be weak, roughly quadratic in
in Eq. (1) is good for brevity, but the apparent simplicity is somewhat misleading, as the underlying operators are complicated and difficult to deal with. Before we explain why, let us describe each term. The form of each term is, assuming any non-linearity in the forward models to be weak, roughly quadratic in ![]() . For this reason, the process of minimising
. For this reason, the process of minimising ![]() is a generalisation of the method of least squares. A cost function which is exactly quadratic is guaranteed to possess a global minimum.
is a generalisation of the method of least squares. A cost function which is exactly quadratic is guaranteed to possess a global minimum.
The state vectors ![]() and
and ![]() exist in the model space and consist of
exist in the model space and consist of ![]() elements. The meaning of each element depends upon the type of model and how it represents the meteorological fields. In a grid-point model, e.g., the vectors will contain information pertaining to the values of each field (e.g.
elements. The meaning of each element depends upon the type of model and how it represents the meteorological fields. In a grid-point model, e.g., the vectors will contain information pertaining to the values of each field (e.g. ![]() and
and ![]() to use standard meteorological symbols for zonal wind, meridional wind, potential temperature, pressure and water vapour mixing ratio respectively) at each grid position. In a spectral model, similar quantities will be stored for the weights of each spectral component at each level. Either way, a huge amount of information is stored in these vectors.
to use standard meteorological symbols for zonal wind, meridional wind, potential temperature, pressure and water vapour mixing ratio respectively) at each grid position. In a spectral model, similar quantities will be stored for the weights of each spectral component at each level. Either way, a huge amount of information is stored in these vectors.
Even greater is the amount of information contained in ![]() which consists of
which consists of ![]() elements. The diagonal elements of
elements. The diagonal elements of ![]() are the variances of the components of the background state (proportional to the square of the uncertainty in
are the variances of the components of the background state (proportional to the square of the uncertainty in ![]() , provided that there are no biases). Due to the structure of
, provided that there are no biases). Due to the structure of ![]() , components of
, components of ![]() with large uncertainty will contribute little influence in the minimization. The off-diagonal elements are a measure of the correlation between different components and contain information regarding how the variational scheme couples different elements of the state vector. Strictly,
with large uncertainty will contribute little influence in the minimization. The off-diagonal elements are a measure of the correlation between different components and contain information regarding how the variational scheme couples different elements of the state vector. Strictly, ![]() will contain covariances not only between the same quantity (e.g.
will contain covariances not only between the same quantity (e.g. ![]() ) at different positions, but also covariances across different quantities (the latter elements are known as multivariate covariances). It is very important to have a reasonable knowledge of the elements of
) at different positions, but also covariances across different quantities (the latter elements are known as multivariate covariances). It is very important to have a reasonable knowledge of the elements of ![]() as it contains crucial statistical information summarizing the behaviour of the system. Fundamentally, it is found by evaluating the matrix,
as it contains crucial statistical information summarizing the behaviour of the system. Fundamentally, it is found by evaluating the matrix,
![]()
![]()
where ![]() is the true state of the atmosphere. This matrix is far too large to calculate, use, or even store in any practical way (let alone invert as required in the cost function). Besides, the true state of the atmosphere in Eq. (2) is unknown. Attempts have been made to represent
is the true state of the atmosphere. This matrix is far too large to calculate, use, or even store in any practical way (let alone invert as required in the cost function). Besides, the true state of the atmosphere in Eq. (2) is unknown. Attempts have been made to represent ![]() with far fewer pieces of information than
with far fewer pieces of information than ![]() and by using approximations to the truth. In weather forecasting, it is usual to transform from the meteorological variables (as listed above) to an alternative set which are not strongly correlated (ie transforming to a set of univariate variables) and to treat vertical and horizontal covariances separately. For the purposes of this report we will not worry about this and presume that we know how to act with the inverse
and by using approximations to the truth. In weather forecasting, it is usual to transform from the meteorological variables (as listed above) to an alternative set which are not strongly correlated (ie transforming to a set of univariate variables) and to treat vertical and horizontal covariances separately. For the purposes of this report we will not worry about this and presume that we know how to act with the inverse ![]() (
(![]() itself must be non-singular).
itself must be non-singular).
![]() represents the observational forward model which appears in the observation term. It has already been mentioned in section 1. It acts directly on the model state
represents the observational forward model which appears in the observation term. It has already been mentioned in section 1. It acts directly on the model state ![]() . The time evolution operator,
. The time evolution operator, ![]() , is required to produce this state given
, is required to produce this state given ![]() . This is done via the sequence,
. This is done via the sequence,
![]()
![]()
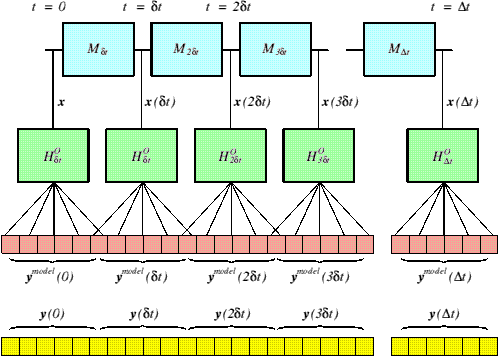
Figure 2: schematic illustration of the purpose of the forward models. The time evolution operators, ![]() (blue boxes) move the model state forward in time, and the observation operators (green boxes),
(blue boxes) move the model state forward in time, and the observation operators (green boxes), ![]() , use each model state to predict the observations close to their proper times.
, use each model state to predict the observations close to their proper times. ![]() could be a NWP forecast model (often linearized) and
could be a NWP forecast model (often linearized) and ![]() is itself subdivided into parts pertaining to the different observation types. The mathematical form of the combined operator is given in Eq. (4). The model-predicted observations form the pink vector which are compared with the actual observations stored in the yellow vector.
is itself subdivided into parts pertaining to the different observation types. The mathematical form of the combined operator is given in Eq. (4). The model-predicted observations form the pink vector which are compared with the actual observations stored in the yellow vector.
Due to the complexity of the ![]() and
and ![]() forward models,
forward models, ![]() is the more complicated of the two penalty terms. Given the initial conditions,
is the more complicated of the two penalty terms. Given the initial conditions, ![]() , the model's prediction of the observations at time
, the model's prediction of the observations at time ![]() is,
is,
![]()
![]()
which is illustrated in Fig. 2 for all times in the time window. The lengths of each observation vector pertaining to the each time can be different in each case to cope with the asynoptic nature of the available observations.
Both the time evolution and observation types of forward model are generally non-linear, although observation operators for some observations involve only linear interpolation. The allowance of non-linear forward models in 4d-Var means, importantly, that information directly from satellite radiances (which are a complicated non-linear function of the temperature, pressure and chemical constituents along the path of the radiation into the instrument) can, in principle, be assimilated directly into the system. The implementation of such operators has had a striking positive impact on the success of weather forecasts [3].
Errors in the observations are represented by the diagonal elements of ![]() . Observations are usually independent pieces of information and are thus uncorrelated. For this reason,
. Observations are usually independent pieces of information and are thus uncorrelated. For this reason, ![]() is often taken to be diagonal and is then easy to invert. Some observations though will be highly pre-processed (e.g. satellite retrieval profiles) and strictly are correlated.
is often taken to be diagonal and is then easy to invert. Some observations though will be highly pre-processed (e.g. satellite retrieval profiles) and strictly are correlated.
The whole process of finding the initial conditions, ![]() can be summarised as the task of finding the set of
can be summarised as the task of finding the set of ![]() elements of
elements of ![]() which minimise the value of
which minimise the value of ![]() . In the limit of linear operators, the definition of
. In the limit of linear operators, the definition of ![]() ensures that it is real and positive semi-definite (
ensures that it is real and positive semi-definite (![]() ). At first, we can only guess what
). At first, we can only guess what ![]() is and its value is refined iteratively by a descent algorithm [4] which we shall not discuss here. The first guess of
is and its value is refined iteratively by a descent algorithm [4] which we shall not discuss here. The first guess of ![]() is often taken to be the background,
is often taken to be the background, ![]() , as it is readily available.
, as it is readily available.
For the descent algorithm to work, it does not actually need to evaluate the value of ![]() itself (although it is a useful diagnostic). Only its gradient with respect to the initial conditions need be found. This is,
itself (although it is a useful diagnostic). Only its gradient with respect to the initial conditions need be found. This is,
![]()
![]()
which will be used, e.g., by a steepest descent algorithm to find how ![]() should be modified to reduce the value of
should be modified to reduce the value of ![]() . At the minimum,
. At the minimum, ![]() is stationary (
is stationary (![]() ). The derivative of Eq. (5) is a column vector containing
). The derivative of Eq. (5) is a column vector containing ![]() components, the
components, the ![]() th one being,
th one being,
![]()
![]()
![]() being the the
being the the ![]() th component of
th component of ![]() . The reason for the presence of the transpose instruction in Eq. (5) is to make the differential operator
. The reason for the presence of the transpose instruction in Eq. (5) is to make the differential operator ![]() (which is by convention a row vector) into a column as required. Although this point seems unimportant at this stage, it is crucial to define our terms properly now as such details will become significant later, especially when we discuss the adjoint method.
(which is by convention a row vector) into a column as required. Although this point seems unimportant at this stage, it is crucial to define our terms properly now as such details will become significant later, especially when we discuss the adjoint method.
In order to see how the gradient will help us minimize ![]() , consider the cost function expanded as a Taylor series about the guess state generalised to the many variables contained in the vector
, consider the cost function expanded as a Taylor series about the guess state generalised to the many variables contained in the vector ![]() . To second order:
. To second order:
![]()
![]()
where ![]() is a guess of the analysis (in the first instance this could be taken as
is a guess of the analysis (in the first instance this could be taken as ![]() ). Contained in the last term of Eq. (7) is the Hessian matrix written in compact notation. Expanded, the Hessian is,
). Contained in the last term of Eq. (7) is the Hessian matrix written in compact notation. Expanded, the Hessian is,
![]()
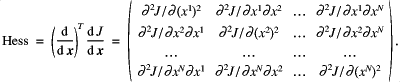
We require the increment, ![]() , which should be added to
, which should be added to ![]() to make
to make ![]() stationary. Differentiating
stationary. Differentiating ![]() in Eq. (7) with respect to
in Eq. (7) with respect to ![]() , and setting to zero for a stationary value gives (this procedure is similar to that made explicitly to the more complicated cost function as shown in section 3.1),
, and setting to zero for a stationary value gives (this procedure is similar to that made explicitly to the more complicated cost function as shown in section 3.1),
![]()
![]()
Rearranged for ![]() , Eq. (9) gives,
, Eq. (9) gives,
![]()
![]()
which shows that the required increment is related to the gradient in a linear sense. This result is nothing more than a generalisation of the Newton-Raphson method, here applied to finding roots of the gradient of a multi-dimensional function. Note that the inverse Hessian has, in general, the effect of altering the direction and length of the gradient vector.
As an aside, this stresses the importance of preconditioning, which is the process of choosing new variables (call the state vector represented in these new variables ![]() , related to
, related to ![]() via a transformation) which are uncorrelated and which have unit variance. For perfectly preconditioned variables, the Hessian measured with respect to changes in the components of
via a transformation) which are uncorrelated and which have unit variance. For perfectly preconditioned variables, the Hessian measured with respect to changes in the components of ![]() would be the unit matrix and, in
would be the unit matrix and, in ![]() -space,
-space,
![]()
![]()
In the remainder of this report we shall return to ![]() -space as we are more interested here in the method of 4d-var, rather than in preconditioning techniques.
-space as we are more interested here in the method of 4d-var, rather than in preconditioning techniques.
We proceed to calculate the gradient of ![]() . In order to do this explicitly from first principles, Eq. (1) can be expanded from its usual 'matrix form' into 'series form',
. In order to do this explicitly from first principles, Eq. (1) can be expanded from its usual 'matrix form' into 'series form',
![]()
![]()
![]()
where the indices ![]() run over model components,
run over model components, ![]() run over observation components, and
run over observation components, and ![]() runs over time steps (each of length
runs over time steps (each of length ![]() ) in the time window. The gradient with respect to the individual component,
) in the time window. The gradient with respect to the individual component, ![]() , is (making use of the product rule),
, is (making use of the product rule),
![]()
![]()
![]()
where ![]() is the
is the ![]() th component of the initial state of the model (in the state of its current guess). This expression can be tidied up by making use of covariance matrix symmetry,
th component of the initial state of the model (in the state of its current guess). This expression can be tidied up by making use of covariance matrix symmetry,
![]()
![]()
![]()
![]()
All components of ![]() can be assembled into a column vector. This is compactly written by reverting to matrix form,
can be assembled into a column vector. This is compactly written by reverting to matrix form,
![]()
![]()
A point on linear algebra: the object ![]() in Eq. (16) is a matrix, known as a Jacobian, and its elements are,
in Eq. (16) is a matrix, known as a Jacobian, and its elements are,
![]()
![]()
which is the sensitivity of the ![]() th model-predicted observation at time
th model-predicted observation at time ![]() due to changes in the
due to changes in the ![]() th component of the model's initial condition vector. It has been transposed in Eq. (16) to work with the matrix notation.
th component of the model's initial condition vector. It has been transposed in Eq. (16) to work with the matrix notation.
Forward models which predict the subset of observations at a time ![]() operate on the model state at that time, yet the sensitivities highlighted in Eq. (17) are made with respect to the initial state of the model. A more natural Jacobian to calculate would be one like,
operate on the model state at that time, yet the sensitivities highlighted in Eq. (17) are made with respect to the initial state of the model. A more natural Jacobian to calculate would be one like,
![]()
![]()
where the derivatives on the left hand side are made with respect to the model state at the same time that the observation forward model is relevant to. We can facilitate this change by using the generalised chain rule [5]. Noting the relationship between ![]() and
and ![]() (Eq. (3)), then the chain rule for derivatives gives,
(Eq. (3)), then the chain rule for derivatives gives,
![]()
![]()
where the non-linear model operators (in bold italic font in Eq. (3)) have been linearised (bold Roman font in Eq. (19), e.g. element ![]() of matrix
of matrix ![]() is
is ![]() ). Inserting this transformation into Eq. (16) yields,
). Inserting this transformation into Eq. (16) yields,
![]()
![]()
In Eq. (20) we have linearized the adjoint time evolution operators (the time evolution operator implied in the innovation vector remains non-linear) as it is unclear how to find the adjoint of non-linear terms (this results in the gradient calculation being approximate). In this context, these operators are perturbation forecast operators. The differential ![]() is effectively a linearization of the forward observation operator. We let,
is effectively a linearization of the forward observation operator. We let,
![]()
![]()
distinguishing again non-linear bold italic operators from matrix bold Roman operators. This makes the expression for the gradient into,
![]()
![]()
In Eq. (22) we have also applied the transpose action to each member in the sequence of time evolution operators of Eq. (20) separately (remember that this involves reversing their order).
We can evaluate the gradient of ![]() with respect to the initial conditions in one of three ways.
with respect to the initial conditions in one of three ways.
![]()
![]()
3. Use the adjoint technique [6] (section 3.3). This is at the heart of 4d-Var and is an efficient means of calculating the gradient. The method does not explicitly store or use matrices. Instead, an operator acts by applying a set of rules (in a program, this would best be done by a subroutine). The absence of matrices makes the transpose (or adjoint) operator difficult to deal with which means that a set of code, pertaining to the adjoint operator, needs to be implemented separately. This is possible if the 'normal' operator is linear, or has been linearized, and there are mechanical methods of doing this given the normal operator [7].
We identify an efficiency in evaluating Eq. (22) if we write out the sum in the following way,
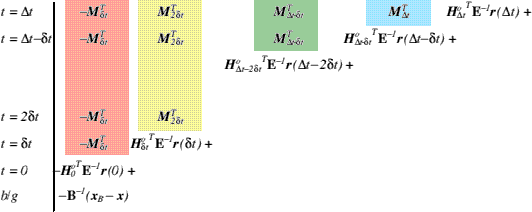
where,
![]()
![]()
is called the residual, and the background term is for time ![]() . Each row in the above sum is a term in the summation of Eq. (22), with the time corresponding to each given on the left hand side. The rows are all added together and the coloured columns serve only to highlight the fact that specific time evolution operators are repeated in different rows (operators of the same colour background are the same). Written in this way, it is possible to see that we can evaluate the series in an alternative order by factorizing common operators according to the following prescription.
. Each row in the above sum is a term in the summation of Eq. (22), with the time corresponding to each given on the left hand side. The rows are all added together and the coloured columns serve only to highlight the fact that specific time evolution operators are repeated in different rows (operators of the same colour background are the same). Written in this way, it is possible to see that we can evaluate the series in an alternative order by factorizing common operators according to the following prescription.
2. Start the next stage of the algorithm at ![]() and evaluate the vector
and evaluate the vector ![]() (call this
(call this ![]() - this appears on the extreme right hand side of the table above). Vectors of this kind (which will also be calculated at earlier times below) are known as adjoint variables.
- this appears on the extreme right hand side of the table above). Vectors of this kind (which will also be calculated at earlier times below) are known as adjoint variables.
3. Integrate the adjoint backwards in time by ![]() . This is done by replacing
. This is done by replacing ![]() with
with ![]() and then calculating the term of Eq. (20) below (using the information,
and then calculating the term of Eq. (20) below (using the information, ![]() , stored from step 1 to calculate
, stored from step 1 to calculate ![]() ). Equation (20) may be proved by mathematical induction working from
). Equation (20) may be proved by mathematical induction working from ![]() to
to ![]() . This action combines residual information from time
. This action combines residual information from time ![]() and adjoint information from time
and adjoint information from time ![]() to form an adjoint state at time
to form an adjoint state at time ![]() . This step comes from the above table: the first term of Eq. (20) appears below each coloured column, the adjoint time evolution operator,
. This step comes from the above table: the first term of Eq. (20) appears below each coloured column, the adjoint time evolution operator, ![]() , is that which appears inside the filled column above, and the adjoint variable,
, is that which appears inside the filled column above, and the adjoint variable, ![]() represents everything to the right of the column.
represents everything to the right of the column.
![]()
![]()
5. Calculate the full gradient by including the background (the full gradient is then used in the descent algorithm to refine our guess),
![]()
![]()
This method is called the adjoint method due to the use of adjoint variables, ![]() , in step 3 (Eq. (25)) and the continuous operation with adjoint (transpose) operators. It is the efficiency of the adjoint technique which has meant that 4d-Var is practical.
, in step 3 (Eq. (25)) and the continuous operation with adjoint (transpose) operators. It is the efficiency of the adjoint technique which has meant that 4d-Var is practical.
Applied in this form, the method has two stages (Fig. 3): (i) a forward integration of the model variables (step 1) followed by (ii) a backward integration of the adjoint variables by the adjoint model (steps 2 to 4). The final step (step 5) just adds on the background contribution. Once the gradient is calculated, the descent algorithm is applied and finds a refined initial condition, ![]() , with which the whole process is repeated. The optimal state is where
, with which the whole process is repeated. The optimal state is where ![]() (by suitable convergence) which means that the cost function has been minimized.
(by suitable convergence) which means that the cost function has been minimized.
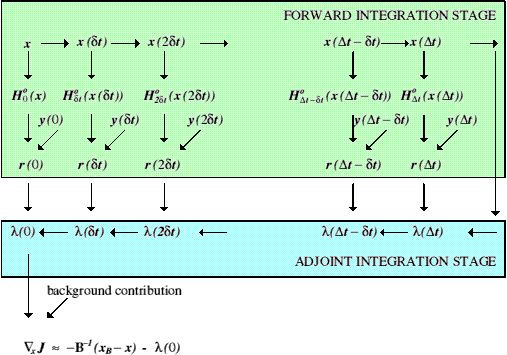
Figure 3: schematic illustration of the adjoint 4d-Var algorithm. The forward integration (green) is essentially the same process as that represented in Fig. 2, but with the additional residual information calculated. The integration of the adjoint variable, ![]() , is done backwards in time (blue box). In this Fig.,
, is done backwards in time (blue box). In this Fig., ![]() is the model state at time
is the model state at time ![]() ,
, ![]() is the observational forward operator,
is the observational forward operator, ![]() is the set of observations at time
is the set of observations at time ![]() ,
, ![]() is the residual (Eq. 19), and
is the residual (Eq. 19), and ![]() is the adjoint at time
is the adjoint at time ![]() . The vector
. The vector ![]() is the gradient (with respect to
is the gradient (with respect to ![]() ) of the observational component of the cost function (Eq. (1)) which is combined with the background gradient to give the total gradient.
) of the observational component of the cost function (Eq. (1)) which is combined with the background gradient to give the total gradient.
Variational data assimilation in which, during a particular assimilation period, no account is taken of the time that observations are taken. The three dimensions are spatial. Although adjoint operators are used, there is, unlike 4d-var, no integration of the adjoint variables back in time.
Variational data assimilation within three space dimensions plus one time dimension. The times that observation are made is resolved by the assimilation system. The adjoint method is at the heart of the technique.
The adjoint is the transpose of a matrix or vector (if complex numbers are present, this should be accompanied by a complex conjugate of the elements). The adjoint turns rows into columns and vice-versa. Some operators are effectively matrices (linear operators), but cannot, due to storage limitations, be stored explicitly. The adjoint operator must then be formulated as a separate operator either manually or by automatic adjoint software. In 4d-Var, adjoint operators (matrices) help integrate the adjoint variables (cost function gradient vectors) backwards in time.
The initial conditions of a forecast model that 'best-fits' (via a sequence of time evolution and observation operators) a set of observations and a background state (also known as optimum analysis). Usually the analysis is initialized before the forecast is run (see the initialization entry).
The window of time in which observations are taken for the optimization (assimilation) process. The forecast period follows.
A model state which is the a-priori guess at the true state of the system. It is a forecast which has been started from the analysis at the previous assimilation cycle and is used, in conjunction with a set of observations, to help find the new analysis state. The background state appears in the cost function (Eq. (1)).
The variables that are actually adjusted during the descent algorithm. These are often not the meteorological variables in model space, but are some transformation involving a new set of parameters and in a new vector space. The gradient of the cost function with respect to each new control variable is required for the descent algorithm. The transformation to control variables is part of the preconditioning process.
A scalar quantity measuring the misfit between a guess of the model state and the background, and the guess (postprocessed to predict the observations) and the observations themselves. The cost function is minimised iteratively in variational data assimilation. Also known as the penalty function.
How one quantity varies with another. A covariance error matrix is a systematic means of storing the statistical information of how errors in each quantity represented depend on the errors in others. The covariance between ![]() and
and ![]() is found from:
is found from: ![]() where
where ![]() mean.
mean.
An algorithm that will adjust the state vector (in control variable space) to yield a new value of the cost function which is lower. The aim of the algorithm is to minimize the cost function. The algorithm requires as its input the gradient of the cost function with respect to each control variable.
Uncertainties of information pertaining to the system. All observations have errors as do all model states. Errors can be systematic (e.g. biases) or random. It is usual to correct for biases (if known) before the assimilation procedure starts and to assume that random errors are Gaussian in nature (this leads to the quadratic form of the cost function in 3d- and 4d-Var). Errors are related to variances.
The period of time following the assimilation period where a model is run freely, and where no observations are available to correct it.
In 4d-Var there are two types of forward model. One kind predicts observations given a model state (observation operators). The other finds future model states from earlier ones (time evolution operator). In 3d-Var only the observation operators are used. 'Forward modelling' is regarded as the 'usual' means of modelling (as opposed to inverse modelling which tries to do the reverse).
The matrix containing all of the second partial derivatives of the cost function, ![]() , with respect to the control variables. Element
, with respect to the control variables. Element ![]() of the Hessian is
of the Hessian is ![]() (see Eq. (8)).
(see Eq. (8)).
The processing of a set of uninitialized initial conditions for a model. The processing could, e.g., be a filter to remove undesirable gravity waves which could otherwise amplify and degrade the forecast.
The difference between the observations and the model's version of the observations, found from the background state. The innovation vector is the residual (Eq. (24)) in the special case that the model integration is started from the background state.
A transformation matrix detailing how components of one set of variables varies with another set.
A fully consistent system where account is taken of the correlations, not just between values of a quantity at different points in space, but between different quantities.
Numerical Weather Prediction (the application of computer models to weather forecasting).
An operator which predicts observations consistent with a model state.
The process of finding the initial conditions of a forecast model to best-fit a set of observations and a background state. The methods of 3d- or 4d-var are optimization techniques.
See cost function.
A variable ![]() is positive (semi) definite if it is bounded by
is positive (semi) definite if it is bounded by ![]() .
.
See observation operator.
The process of choosing new control variables which are exactly, or approximately uncorrelated, and form a unit Hessian matrix. In a perfectly preconditioned system of equations, contours of constant cost function are circles in the new control variable space and the preconditioning number is unity.
The ratio of the highest to the smallest eigenvalues of the Hessian. In a perfectly preconditioned system of equations, the preconditioning number is unity.
The difference between an observation and the model's version of it. The residual vector is a structure containing many such differences, each an element of the vector in Eq. (24).
A formulation of a 4d-Var data assimilation system that assumes a perfect model, or where no account is taken of model error (as assumed here).
The set of rules which advances the model state forward in time (see Eq. (3)).
This is the situation where one type of quantity is, or assumed to be, uncorrelated with another. Meteorological variables are rarely uncorrelated with each other (the multivariate case), but sometimes new variables are chosen that are approximately uncorrelated. This is part of the preconditioning procedure.
The variance of a variable is related to the error by: ![]() (for a single measurement). The variance of the quantity
(for a single measurement). The variance of the quantity ![]() is found from:
is found from: ![]() where
where ![]() is the mean. A variance is the special case of a covariance where both quantities (
is the mean. A variance is the special case of a covariance where both quantities (![]() and
and ![]() in the glossary entry for covariance) are the same. Variances occupy the diagonal elements of a covariance matrix.
in the glossary entry for covariance) are the same. Variances occupy the diagonal elements of a covariance matrix.
A formulation of a 4d-Var data assimilation system that takes into account model error.